
¿Porque escribir esto?
Simplemente porque creo que cuando uno lee y practica, aprende, pero cuando uno lee, practica y escribe, aprende el doble.
Se que existen muchos textos (y de muy buena calidad) pero hablando con algunas personas de mi Discord y viendo que existían ciertas dudas ante algunos CTFs que hacíamos, tome las riendas y me aventure a escribir esta serie de papers con el objetivo de seguir mejorando cada día mis skills como también poder ayudar a guiar a otras personas en el Binary Exploitation.
Está demás decir, son libres de realizar sugerencias constructivas si encuentran algún error o no están de acuerdo con algún concepto escrito y con gusto lo revisare.
[*] Conocimientos previos recomendables [*]
Es ideal contar con conocimientos de Assembler, C/C++, Arquitecturas x86_64, GDB y Python Scripting. Aclarar también que estaré realizando esto desde mi [Arch Linux].
Lectura recomendada: https://eli.thegreenplace.net/2011/02/04/where-the-top-of-the-stack-is-on-x86/
¿Que es el Binary Exploitation?
Podríamos reducirlo a encontrar una vulnerabilidad en un programa/binario y explotarlo para obtener el control de una shell o modificar las funciones del mismo.
La parte del lenguaje que una computadora entiende se llama “binario”.
Las computadoras operan en binario, lo que significa que almacenan datos y hacen cálculos usando solo 0s y 1s. Un solo dígito binario puede representar solo Verdadero (1) o Falso (0) en términos lógicos simples. Cada lenguaje de programación tiene sus propias características, aunque a menudo comparten similitudes. La idea principal es convertir una debilidad en una ventaja, aprovechando errores o problemas para hacer que el programa haga algo que no estaba destinado a hacer.
Breve repaso: Varios Conceptos básicos.
Voy a tratar de explicar algunos conceptos muy básicos a modo de refrescar la memoria, pero es conveniente que profundicen los temas por ustedes mismos para poder empezar a trabajar en la explotacion de binarios.
¿Que son los registros de un procesador?
Registros x86 (32bits)
Los registros son como variables internas para un procesador. Ubicaciones de almacenamiento de datos de alta velocidad. Entre ellos podemos mencionar los siguientes que son considerados registros de “propósito general” y según sus siglas significan:
- EAX -> Registro Acumulador
- EBX -> Registro Base
- ECX -> Registro Contador
- EDX -> Registro de Datos
Después hay otro grupo de registros de propósito general también, los cuales son conocidos también como Punteros e indizadores y estos son:
- ESP -> Puntero de Pila (Stack Pointer)
- EBP -> Puntero Base (Base Pointer)
- ESI -> Indice de Origen (Source Index)
- EDI -> Indice de Destino (Destination Index)
Los registros ESP y EBP son nombrados punteros porque almacenan direcciones de (32bits) que literalmente apuntan a esa ubicación en la memoria.
Son registros importantes para el correcto funcionamiento de un programa y gestión de la memoria.
Los registros que le siguen, ESI y EDI, son también registros punteros que indican el origen, y el destino, cuando se debe leer o cargar datos.
También tenemos el registro EIP, que es un registro puntero de instrucción, que señala básicamente la instrucción que el procesador esta leyendo en ese momento. (Imaginemos como si leyéramos un libro y con nuestro dedo indice vamos siguiendo cada palabra de esa linea de texto)
Por ultimo, mencionar el registro EFLAGS (Extended Flags), y se utiliza para almacenar una serie de banderas (o flags) que indican el estado y el resultado de operaciones en la CPU. Estas banderas son esenciales para el funcionamiento del procesador y se utilizan para controlar el flujo de ejecución del programa y para tomar decisiones basadas en el resultado de operaciones aritméticas y lógicas.
Registros x64 (64bits)
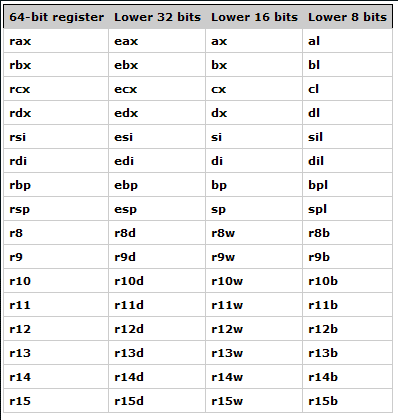
La arquitectura x64 amplía los 8 registros de propósito general de x86 (anteriormente mencionados) para que sean de 64 bits y ademas agrega 8 nuevos registros de 64 bits. Los nombres de estos registros comienzan con una letra R, así por ejemplo la extensión de 64 bits de EAX se llama RAX. Los nuevos registros van desde R8 a R15. Adjunto una imagen para mejor entendimiento.
Entendiendo la Segmentación de Memoria
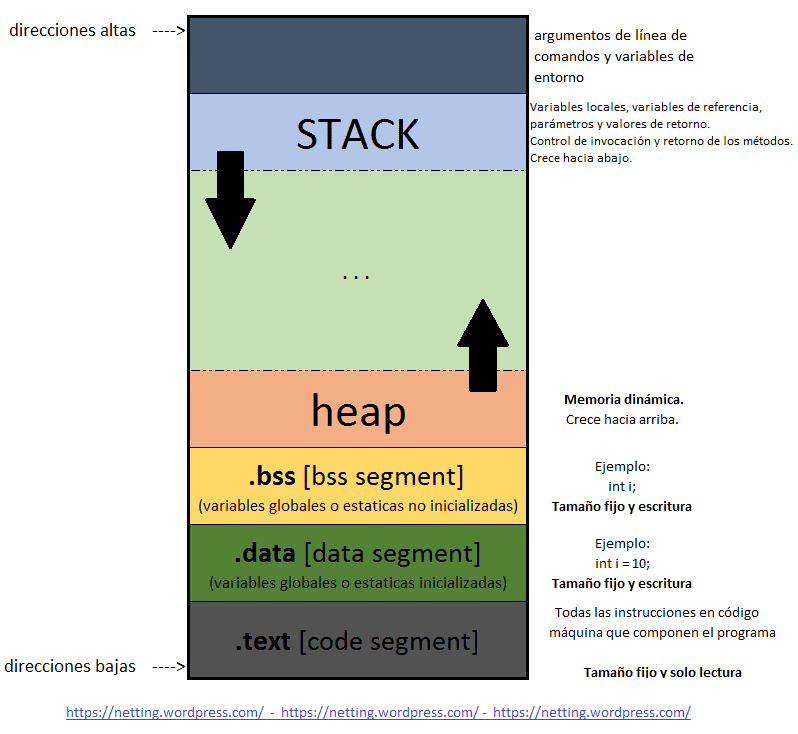
La memoria de un programa compilado se puede dividir en 5 segmentos:
- text
- data
- bss
- heap
- stack
Cada uno de estos segmentos representa una parte especifica de la memoria que es reservada para un determinado propósito:
Segmento de [ .text ]
También es conocido como segmento de código, y acá es donde se encuentran las instrucciones ejecutables del programa en assembler. Este segmento es de Solo lectura, lo que significa que el código almacenado no podrá ser modificado durante la ejecución del mismo.
Segmento de [ .data y .bss ]
Los segmentos de datos y bss se usan para almacenar variables de programa globales y estáticas. En el segmento de ‘.data‘ se encuentran las variables estáticas y globales inicializadas. Esto significa que contienen valores asignados específicos en el momento de la declaración por ejemplo:
Cint x = 8;
Mientras que en el segmento de ‘.bss‘ es lo contrario, están las variables no inicializadas. Esto significa que contiene variables que no han sido declaradas con algún valor en especifico, se inicializan en tiempo de ejecución con un valor predeterminado. Un ejemplo:
int a;
char myBuffer[70];Segmento del [ HEAP ]
Este segmento puede ser directamente controlado por el programador. Se utiliza para almacenar datos dinámicos, es decir datos cuyo tamaño o duración no se conoce de antemano y puede ir cambiando a medida que se ejecuta el programa.
Lenguajes como C/C++ permiten trabajar directamente con el HEAP a través de funciones como malloc y free en C o new y delete en C++. Lenguajes como Python gestionan automáticamente la memoria en el Heap.
Segmento del [ STACK ]
En español “Pila”. En este segmento a diferencia del Heap se utiliza para almacenar variables locales y datos relacionados con la ejecución de las funciones. Cada vez que una función es llamada, se agrega un nuevo Marco de Pila o en ingles Stack Frame que contiene variables locales, parámetros de la función y una dirección de retorno. (RET).
La estructura de la STACK es de tipo LIFO del ingles (Last In, First Out), lo que significa “ultimo en entrar, primero en salir“.
Un ejemplo gráfico de esto para entender mejor:
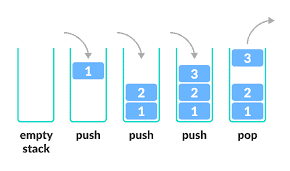
En la arquitectura Intel, la información de cuatro bytes de longitud se denomina “palabra doble” o “dword”.
Esto significa que el último “dword” almacenado en la memoria será el primero en recuperarse. Las operaciones permitidas en la pila son PUSH y POP.
PUSH se utiliza para insertar un “dword” de datos en la pila, y POP recupera el último “dword” de la pila.
Profundizando: Function Calls & STACK
Voy a entrar mas en detalle sobre el funcionamiento puntual de las function calls y la pila o (STACK). Como mencionamos mas arriba, en cada function call, se activa un marco de pila o stack frame para incorporar lo siguiente:
- Los parámetros de la función.
- La dirección de retorno, que es útil para almacenar la dirección de memoria de la siguiente instrucción que se llama, después de que la función retorna.
- El puntero de marco (pointer frame), que se utiliza para obtener una referencia al marco actual de la pila y otorgar acceso a las variables locales y los parámetros de la función.
- Y las variables locales de una función.
En la arquitectura x86, tres registros se convierten con un papel crucial en la STACK, estos son “EIP“, “EBP” y “ESP“. (En x64 RIP, RBP, RSP).
“EIP” como dijimos, significa (Puntero de Instrucción Extendido), es un registro de solo lectura y contiene la ubicación de la siguiente instrucción a leer en el programa.
“EBP” significa (Puntero de Base Extendido de la Pila), y su objetivo es señalar la ubicación base de la “Stack”. Y tiene la intención de decirte dónde estás en la “Stack”. Esto implica que
“ESP” marca el punto más alto de la “Pila”.
El registro “EBP” es importante porque proporciona un punto de permanencia en la memoria, y podemos hacer referencia a muchas cosas a ese valor. Cuando se llama a la función dentro de un programa y tenemos algunos parámetros para enviarle, “EBP” hace referencia continuamente a las posiciones en la memoria al igual que las variables locales, como se muestra en la imagen a continuación.
(Fuente: https://whitehatinstitute.com/)
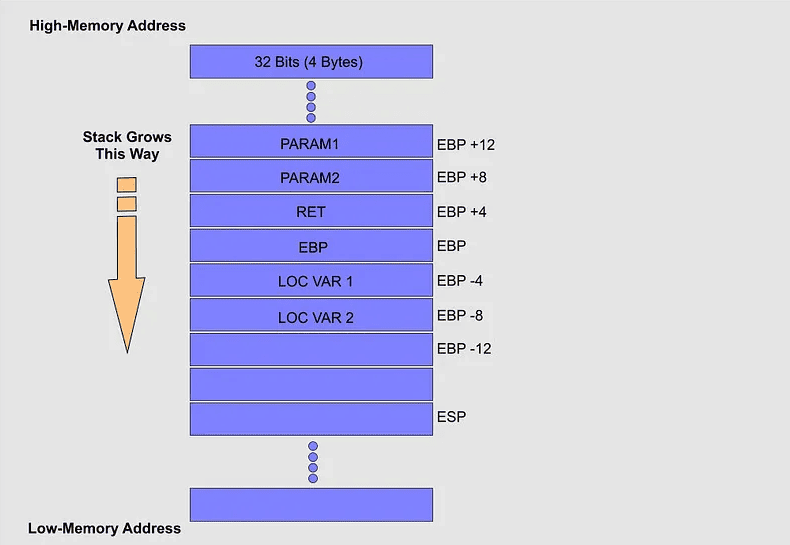
Sabemos que la memoria esta compuesta por direcciones de Bajo numero de memoria y direcciones de alta numero de memoria. Siguiendo el ejemplo si enviamos una cadena formada por 12 caracteres “A”. La memoria se verá como la siguiente figura:
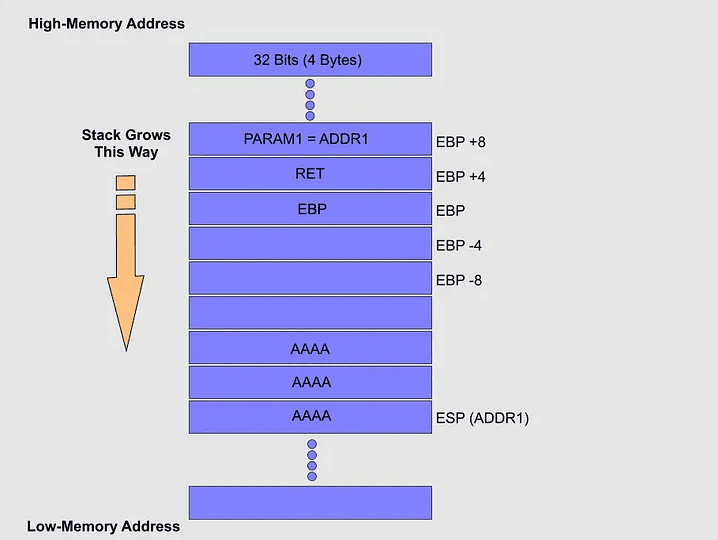
Al analizar esta imagen, vemos que “PARAM1” apunta a la ubicación donde se guarda la información en la “Stack” y, como probablemente ya sabemos, “ESP” se enfoca en la parte superior de la pila, por lo que la cadena se duplica desde “ADDR1” 4 bytes. uno tras otro a una memoria superior, y esto sucede porque es la mejor manera de permanecer dentro de la “Stack”.
En el caso de que la función no controle la longitud del buffer en un Input por ejemplo y enviemos una gran cantidad de caracteres “A”, podríamos terminar con un caso como el de la imagen a continuación:
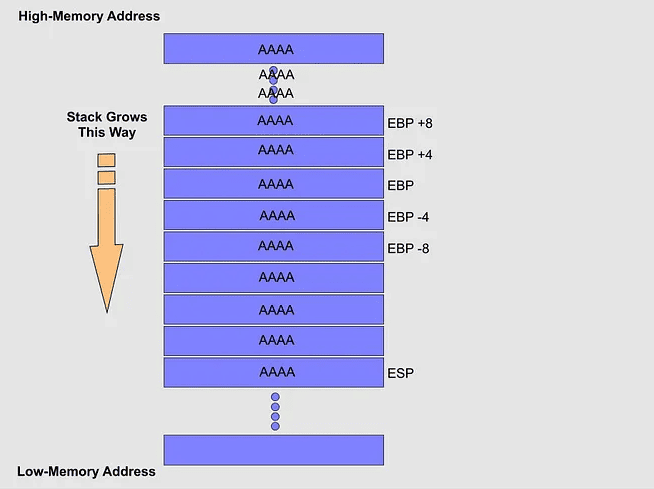
El registro “EIP” se va a sobrescribir con los caracteres “A”, por ende estaríamos modificando la dirección de regreso para la ejecución de la próxima instrucción.. Al no tener una dirección ‘real’ o ‘existente’ el programa se detendrá.
¿Que es la GLIBC?
Son las siglas de GNU C Library. Es una librería Open Source y toma la forma de un “.so”, (Shared Object) lo que seria equivalente a un “.dll” en Windows.
Esta librería de C proporciona y define las famosas syscalls o llamadas al sistema, entre otras funciones importantes. Prácticamente es utilizada por casi todos los programas y sistemas basados en el kernel de Linux.
La mayoría de los sistemas operativos de Linux se distribuyen con una versión especifica de GLIBC, y esta perdura en lo que abarca su sistema de soporte. A excepciones de distribuciones como ARCH en la que es un sistema rolling release y debido a esto, va actualizando su versión de GLIBC constantemente.
Verificando versión GLIBC de nuestro sistema.
Para verificar la versión podemos tipear lo siguiente (recuerden que estoy en Arch, podría discrepar al sistema que estén corriendo ustedes)
ldd --version ldd
Otra alternativa:
ldd `which ping` |grep libc.soLuego ejecuto directamente el path absoluto:
/usr/lib/libc.so.6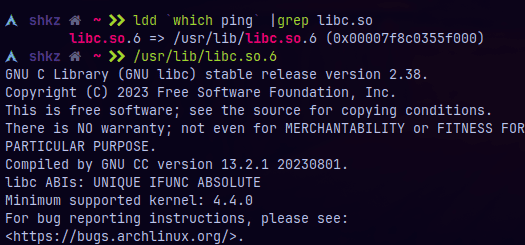
Hasta acá la primer parte del paper.. y luego de este mini repaso pasamos a lo divertido:
>> Buffer Overflow <<
Muchas gracias,
shkz | MyHack.tech


